
索引的创建与设计原则
1. 索引的声明与使用
1.1 索引的分类
MySQL 的索引主要有:普通索引、唯一性索引、全文索引、单列索引、多列索引和空间索引等
- 按功能 分,有 4 种:普通索引、唯一索引、主键索引、全文索引。
- 按物理实现方式 分,有 2 种:聚簇索引 和 非聚簇索引
- 按 作用字段个数 分:单列索引 和 联合索引
-
普通索引
创建时无任何附加条件,只是用于增加查询效率,可以作用在任何数据类型中 -
唯一性索引
使用UNIQUE 参数设置索引为唯一索引,创建时,该字段必须有唯一性约束,允许为 null 值 -
主键索引
主键索引 就是唯一性索引 + 非空约束,一张表中最多只有一个主键索引 -
单列索引
作用在一个字段的索引 -
多列(组合、联合)索引
作用在多个字段的索引。但是只有查询条件中使用了第一个字段时索引才会被使用。 -
全文索引
全文是目前搜索引擎使用的一种关键技术。使用分词技术等算法分析出文本文字中关键字的频率和重要性,按一定算法规则筛选出我们想要的搜索结果。适用于大型数据集 -
空间索引
只可以建立在空间数据类型上,使用参数SPATIAL可以设置索引为空间索引
小结:不同的存储引擎支持的索引不同
InnoDB:支持 B-tree,Full-text 等索引,不支持 Hash 索引
MyISAM:支持 B-tree,Full-text 等索引,不支持 Hash 索引
Memory:支持 B-tree,Hash 等索引,不支持 Full-text 索引
NDB:支持 Hash 索引,不支持 B-tree、Full-text 等索引
Archive:不支持 B-tree,Full-text 、 Hash 索引
1.2 创建索引
在创建表时,可以指定索引列。修改表时,也可为表创建索引。也可以使用 CREATE INDEX 在已存在的表上添加索引
1. 创建表时创建索引
隐式方式创建索引。声明主键约束、唯一性约束、外键约束的字段上,会自动的添加索引
CREATE DATABASE dbtest2;
USE dbtest2;
CREATE TABLE dept(
dept_id INT PRIMARY KEY AUTO_INCREMENT,
dept_name VARCHAR(20)
);
CREATE TABLE emp(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
emp_name VARCHAR(20) UNIQUE,
dept_id INT,
CONSTRAINT emp_dept_id_fk FOREIGN KEY(dept_id) REFERENCES dept(dept_id)
);
显式创建
CREATE TABLE 表名(字段名 字段类型,..)
[UNIQUE/FULLTEXT/SPATIAL] [INDEX/KEY] 索引名字 [字段,../length] {ASC/DESC}
UNIQUE、FULLTEXT、SPATIAL作为可选参数,分别表示为唯一索引、全文索引和空间索引INDEX与KEY意思相同,可以相互替换length是可选参数,表示索引的长度,只有字符串类型的字段才可以指定索引长度ASC或DESC指定升序或降序的索引值存储
举例:
CREATE TABLE book(
book_id INT,
book_name VARCHAR(100),
authors VARCHAR(100),
info VARCHAR(100),
comment VARCHAR(100),
year_publication YEAR,
声明索引
INDEX idx_bname(book_name)
);
查看 索引
SHOW CREATE TABLE book;
或
SHOW INDEX FROM book;
性能分析工具:EXPLAIN
EXPLAIN SELECT * FROM book_name = 'mysql高级';
举例:
1.1 唯一索引
插入有唯一索引字段数据时,要保证唯一值,可以为 null 值
CREATE TABLE book1(
book_id INT,
book_name VARCHAR(100),
authors VARCHAR(100),
info VARCHAR(100),
comment VARCHAR(100),
year_publication YEAR,
声明索引
UNIQUE INDEX uk_idx_cmt(book_name)
);
1.2 主键索引
只能通过定义主键约束的方式定义主键索引
CREATE TABLE book2(
book_id INT PRIMARY KEY AUTO_INCREMENT,
book_name VARCHAR(100),
authors VARCHAR(100),
info VARCHAR(100),
comment VARCHAR(100),
year_publication YEAR,
);
只能通过删除主键约束的方式删除主键索引
ALTER TABLE book2
DROP PRIMARY KEY;
1.3 联合索引
CREATE TABLE book3(
book_id INT PRIMARY KEY AUTO_INCREMENT,
book_name VARCHAR(100),
authors VARCHAR(100),
info VARCHAR(100),
comment VARCHAR(100),
year_publication YEAR,
声明索引
INDEX mul_bid_bname_info(book_id,book_name,info)
);
最左前缀原则:
必须要有最左边的字段才可以用到索引
EXPLAIN SELECT * FROM book3 where book_id = 1001 AND book_name = 'mysql';
无法使用索引:
EXPLAIN SELECT * FROM book3 where book_name = 'mysql';
1.4 全文索引
只可以为 CHAR、VARCHAR 和 TEXT 类型的字段创建索引
创建:
CREATE TABLE test4(
id INT NOT NULL,
name char(30) NOT NULL,
age INT NOT NULL,
info VARCHAR(255),
FULLTEXT INDEX futxt_idx_info(info(50))
);
2. 为已经存在的表创建索引
CREATE TABLE book5(
book_id INT PRIMARY KEY AUTO_INCREMENT,
book_name VARCHAR(100),
authors VARCHAR(100),
info VARCHAR(100),
comment VARCHAR(100),
year_publication YEAR
);
方式一:ALTER TABLE … ADD …
ALTER TABLE book5 ADD INDEX idx_cmt(comment);
ALTER TABLE book5 ADD UNIQUE INDEX uk_idx_bname(book_name);
ALTER TABLE book5 ADD INDEX mul_bid_bname_info(book_id,book_name,info);
方式二:CREATE INDEX… ON …
CREATE INDEX idx_cmt ON book5(comment);
CREATE UNIQUE INDEX uk_idx_bname ON book5(book_name);
CREATE INDEX uk_idx_bname ON book5(book_id,book_name,info);
1.3 删除索引
方式一: ALTER TABLE 表名 DROP INDEX 索引名(字段名);
ALTER TABLE book5 DROP INDEX idx_cmt;
添加 AUTO_INCREMENT 约束的字段的唯一索引不可被删除
方式二:DROP INDEX 索引名 ON 表名;
DROP INDEX uk_idx_bname ON book5;
若删除字段时,该字段为索引的组成部分,则在索引中该字段也会被删除。若组合索引的索引字段都被删除,则该索引会被删除
2. MySQL8.0 索引新特性
2.1 支持降序索引
InnoDB 才支持降序索引
举例:
CREATE TABLE test1(a int,b int,index idx_a_b(a ASC,b desc));
在 MySQL 5.7 中查看表结构
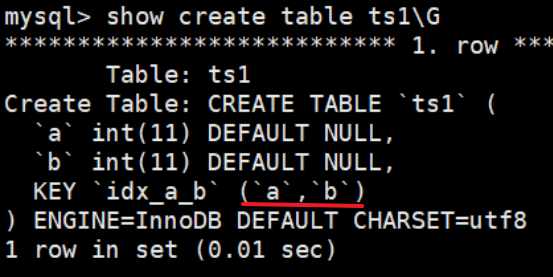
可以看出,索引仍然是默认的升序。在使用索引遍历 b 字段时会逆序遍历。严重影响效率
MySQL 8.0 中
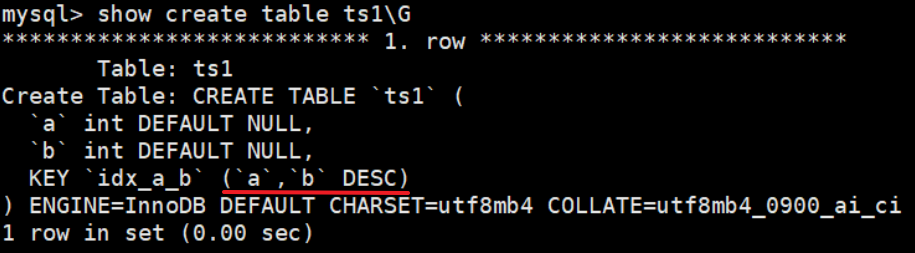
索引遍历时已经是降序的了。
2.2 隐藏索引
MySQL 5.7 及之前,删除索引只能够显式的删除。如果发现删除索引后出现错误,又只能重新创建索引。若此时表中数据量非常大,则此过程会消耗较多的资源,操作成本较高
从 MySQL8.0 开始支持 隐藏索引(invisible indexes) ,只需要将待删除的索引设置为隐藏索引,让查询优化器不再使用这个索引(即使使用 force index(强制使用索引),也不会使用),确认该索引设置为隐藏索引后系统不受任何影响,就可以彻底的删除该索引。先设置为隐藏索引再删除 叫:软删除
若想要验证索引删除后的查询性能影响,也可先隐藏该索引
主键不可设置为隐藏索引
索引默认为可见,可以在 CREATE TABLE,CREATE INDEX 或 ALTER TABLE 等语句时使用 VISIBLE 或者 INVISIBLE 关键字设置索引的可见性
- 在创建表时设置
CREATE TABLE book6(
book_id INT PRIMARY KEY AUTO_INCREMENT,
book_name VARCHAR(100),
authors VARCHAR(100),
info VARCHAR(100),
comment VARCHAR(100),
year_publication YEAR,
创建不可见的索引
INDEX idx_cmt(comment) invisible
);
- 修改表时
ALTER TABLE book6
ADD UNIQUE INDEX uk_idx_bname(book_name) invisible;
- 创建索引时
CREATE INDEX idx_year_pub ON book6(year_publication) invisible;
- 修改索引时
ALTER TABLE book6
ALTER INDEX idx_year_pub invisible; 不可见
ALTER TABLE book6
ALTER INDEX idx_year_pub visible; 可见
注意:当索引隐藏时,插入数据仍然会更新索引。倘若该索引长期不使用,则可以删除(会影响插入的性能)
- 可以让隐藏索引对查询优化器可见
3. 索引的设计原则
3.1 哪些情况适合创建索引
1. 字段的数值唯一性的限制
如果某个字段的值是唯一性的,则可以直接为其添加 唯一索引,或者主键索引,可以大大提高查询速度
业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引(阿里规范)
说明:不要以为唯一索引印影响了 insert 速度,这是速度损耗是可以忽略的,但提高查找速度是明显的
2. 频繁作为 WHERE 查询条件的字段
若某个字段在 SELECT 语句中经常作为 WHERE 条件中,则应该为这个字段创建索引。创建普通索引可以大幅度提升查询效率
3. 经常 GROUP BY 和 ORDER BY 的列
索引会使数据以某种顺序进行存储或查询,所以使用 GROUP BY 分组查询 或 使用 ORDER BY 进行排序时,应该对分组/排序字段进行索引。若有多个字段,则可以建立联合索引
在为 GROUP BY 和 ORDER BY 建立联合索引时,顺序应该是 GROUP BY 字段在前,这样效率最高(因为是执行顺序是先 GROUP BY 再 ORDER BY)
4. UPDATE、DELETE 的 WHERE 条件列
5. DISTINCT 字段需要创建索引
6. 多表 JOIN 连接时,创建索引的注意事项
- 连接表的数量尽量不要超过 3 张
- 对 WHERE 条件创建索引
- 用来作为连接条件的字段创建索引,注意该字段在不同表中的类型必须一致
7. 使用列的类型小的创建索引
8. 使用字符串前缀创建索引
若字符串很长,则存储会占用很大的存储空间。创建索引时
- B+ 树索引 叶子节点需要把该列的完整数据存储起来,较费时浪费存储空间
- 在进行字符串比较时会占用更多的时间
解决方案:
前缀索引:可以截取字符串前面的部分内容建立索引。
虽然无法精确的定位到需要的记录位置,但是可以定位到相应前缀的位置,回表后再进行查询完整的字符串值。
截取长度的选择:
公式
count(distinct left(列名,索引长度))/count(*) 超过33% 就可以算是比较高效的索引
例如:
select count(distinct left(address,10)) / count(*) as sub10, ---截取前10个字符
count(distinct left(address,15)) / count(*) as sub11, ---截取前15个字符
count(distinct left(address,20)) / count(*) as sub12, ---截取前20个字符
count(distinct left(address,25)) / count(*) as sub13 ---截取前25个字符
from shop;
越接近为 1 结果最好。若区别不大,则选择截取最少的
问题: 索引前缀对排序的影响
若使用了前缀索引
SELECT *
FROM shop
ORDER BY address
LIMIT 12;
二级索引中不包含完整的 address 列信息,所以无法对前12 字符相同,后面的字符不相同的记录进行排序,也就是使用索引列前缀的方式无法支持使用索引排序,只能使用文件排序
拓展:Alibaba《Java开发手册》
【强制】:在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,按照实际文本区分决定索引长度
说明:一般字符串类型数据,索引长度为 20,区分度会达到 90% 以上。
9. 区分度高(散列性高)的列适合作为索引
列的基数 指的是某一列中不重复数据的个数。例如:2,5,8,2,5,8,2,5,8 该列的基数为 3。
在数据行数一致时,列的基数越大,该列中的值就越分散;列的基数越小,该列中的值越集中
10. 使用最频繁的列放在联合索引的左侧
11. 多个字段都要创建索引的情况下,联合索引优于单列索引
3.2 限制索引的数量
建议单张表的索引数量不超过 6 个
- 每个索引都需要占用
磁盘空间 - 会影响
INSERT 、DELETE、UPDATE 等语句的性能 - 查询优化器在选择如何优化查询时,会
评估每个可以使用的索引(若索引越多耗时越长),以生成最好的执行计划,若同时有很多个索引都可以用来查询时,会增加 MySQL 优化器生成执行计划的时间,降低查询性能
3.3 哪些情况不适合创建索引
1. 在 where 中使用不到的字段,不要设置索引
WHERE 条件(包括 GROUP BY、ORDER BY)中用不到的字段,不需要创建索引
2. 数据量小的表最好不要使用索引
少于 1000 个
3. 有大量重复数据的列不要创建索引
例如:性别字段。
当数据重复度高于 10%,不要创建
会严重降低数据更新速度
4. 避免对经常更新的表创建过多的索引
- 更新数据时,还要更新索引
- 对经常更新的表创建过多的索引,并且索引中的列较少。虽然会提升查询速度,但是会降低更新表的速度
5. 不建议使用无序的值作为索引
6. 删除不再使用或很少使用的索引
7. 不要定义冗余或重复的索引
例如:
- 冗余索引
CREATE TABLE person_info(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number),
KEY idx_name (name(10))
);
我们可以查询 name 字段时,会使用联合索引,不会使用 idx_name。所以 idx_name 就是一个冗余索引。只会增加维护成本
- 重复索引
为某个列重复创建了索引
CREATE TABLE repeat_index_demo (
col1 INT PRIMARY KEY,
col2 INT,
UNIQUE uk_idx_c1 (col1),
INDEX idx_c1 (col1)
);
3.4 小结
索引是双刃剑,可以提升查询效率,但也会降低插入和更新的速度并且占用磁盘空间
{kind=link}
{kind=link}