
索引优化与查询优化
- 索引失效、没有充分利用索引---索引建立
- 关联查询太多 JOIN(设计缺陷或不得已的需求)---SQL 优化
- 服务器调优及各个参数设置(缓冲、线程数等)---调整 my.cnf
- 数据过多 --- 分库分表
SQL 查询优化可以分为:物理查询优化 和 逻辑查询优化
- 物理查询优化:通过
索引和表连接方式等技术进行优给,重点需要掌握索引的使用 - 逻辑查询优化:通过 SQL 等价变换提示效率。
1. 数据准备
2.索引失效案例
提高性能最有效的方式是对数据表设计合理的索引。索引提供了高效访问数据的方法,并且加快了访问速度。
- 使用
索引可以快速的定位表中某条记录,从而提高数据库查询的速度,提高性能 - 若查询时没有使用索引,查询语句就会
扫描表中的所有记录。速度较慢
最终执行计划中是否使用索引,是有关于查询优化器生成的执行计划决定。 优化器是基于 cost开销(CostBaseOptimizer) ,怎么样开销小就怎么来。另外 SQL 语句是否使用索引,跟数据库版本、数据量、数据选择度都有关系
2.1 全值匹配
举例:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId = 4;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 and classId = 4 AND name = 'abcd';
建立索引前所用时间:0.208s
CREATE INDEX idx_age ON student(age);
CREATE INDEX idx_age_classid ON student(age,classId);
CREATE INDEX idx_age_classid_name ON student(age,classId,name);
创建索引后:0.081s
2.2 最佳左前缀法则
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abcd';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classid = 1 AND student.name = 'abcd';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE classid = 4 AND student.age = 30 AND student.name = 'abcd';
where 条件中要有索引最左边的字段,若想充分利用索引,则不能跳过字段,否则只能使用一部分
where 条件中要使用索引必须要按照索引建立的顺序,一旦跳过某个字段,索引后面的字段将无法被使用
2.3 主键插入顺序
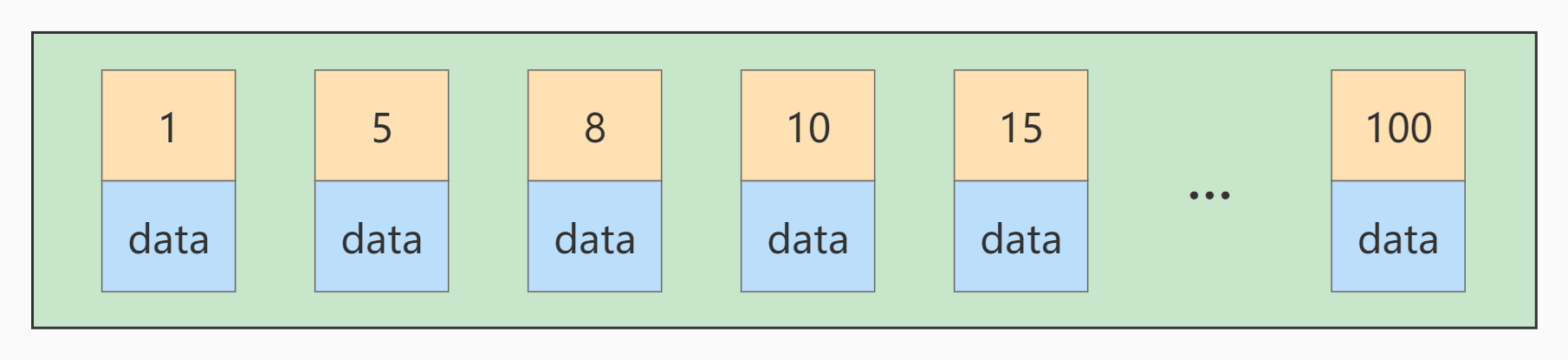 若此时再插入一条主键值为 9 的记录
若此时再插入一条主键值为 9 的记录
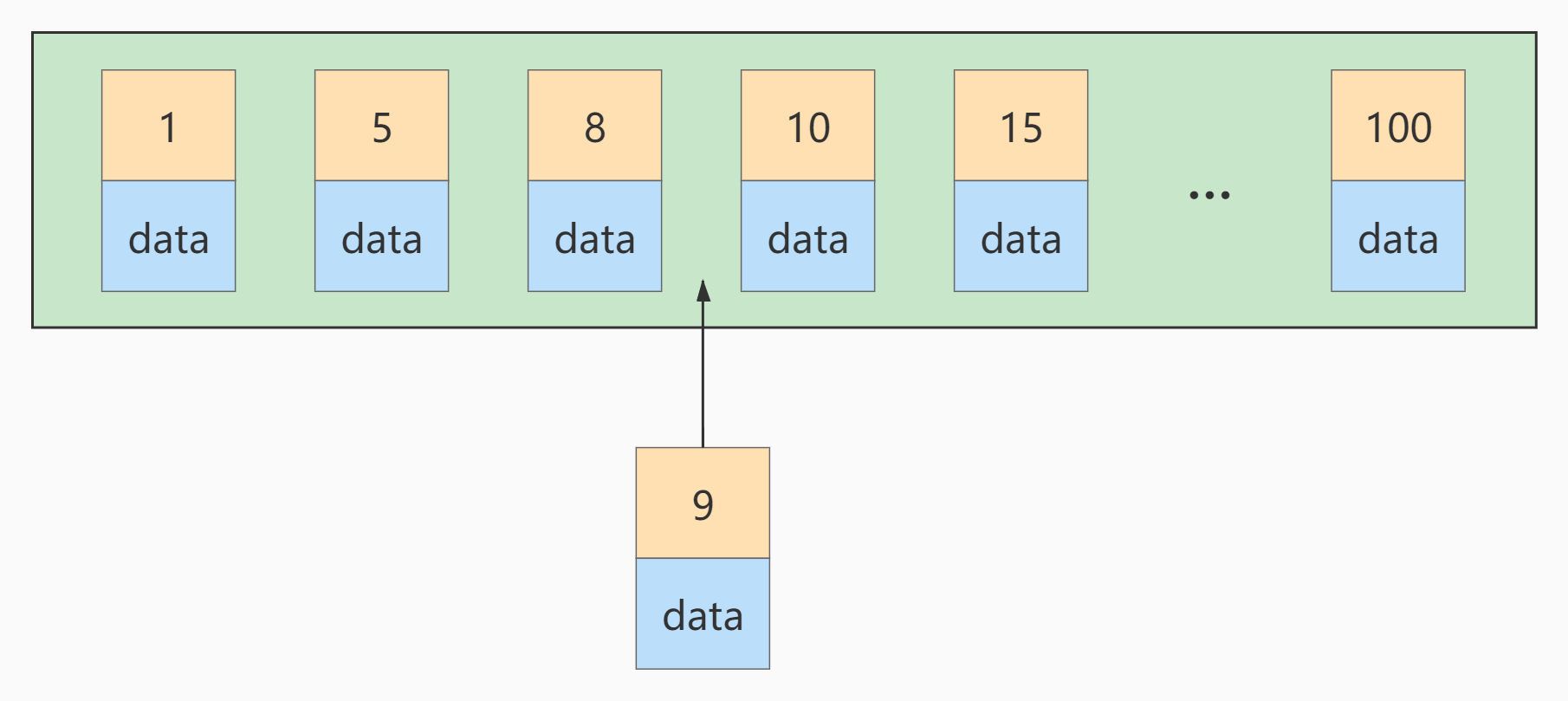
会造成页分裂。我们应该尽量避免这种情况,最好让插入的数据的主键值依次递增。建议:让非核心表主键有 AUTO_INCREMENT
2.4 计算、函数、类型转换(自动或手动)导致索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
优于
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
出现计算、函数 时会导致索引失效
2.5 类型转换导致索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name = '123';
优于
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name = 123;
无论是显式还是隐式的类型转换都会导致索引失效
2.6 范围条件中右边的列索引失效
创建联合索引时列的顺序。若联合索引中的字段是作为范围条件的查询,则会导致定义联合索引时声明该字段后的字段无法使用到索引
CREATE INDEX idx_age_classId_name ON student(age,classId,name);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age = 30 AND student.classId > 20 AND student.name = 'abc';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age = 30 AND student.name = 'abc' AND student.classId > 20;
以上查询都只可用到 age字段和 classId 的索引。由于 classId 是范围查询,则联合索引字段 classId 后的字段无法使用索引(即 name 字段无法使用索引)

CREATE INDEX idx_age_name_cid ON student(age,name,classId);
使用该索引,则不会失效

开发中范围查询。应该将查询条件放置到 where 语句的最后。(重点:创建的联合索引中,务必将范围涉及到的字段写在最后)
2.7 不等于(!= 或 <> ) 索引失效
特例:覆盖索引
2.8 is null 可以使用索引,is not null 无法使用索引
结论:最好在设计表时为
字段设置 NOT NULL 约束。若真有需求,则可以将 INT 类型字段设置为 0,将字符类型的默认值设置为空串('')。 同理:在查询中使用not like也无法使用索引,导致全表扫描。
2.9 like 以通配符%开头索引失效
拓展:《Java 开发手册》 【强制】:页面搜索禁止左模糊或者全模糊。若有需要走搜索引擎解决。
2.10 OR 前后存在非索引的列,索引失效
2.11 数据库和表的字符集统一使用 utf8mb4
统一字符集 可以避免因字符集不同转换所产生的乱码。不同的字符集进行比较前需要进行转换会造成索引失效
2.12 建议
- 对于单列索引,尽量选择针对当前 query 过滤性 更好的索引
- 在选择组合索引时,当前 query 中过滤性最好的字段在索引创建时,位置越前越好
- 在选择组合索引时,尽量选择能够包含当前 query 中的 where 子句中更多字段的索引
- 在选择组合索引时,如果某个字段可能出现范围查询时,尽量将该字段放在索引次序的最后面
3. 关联查询优化
3.1 左外连接
没有索引的情况下:
EXPLAIN SELECT SQL_NO_CACHE * FROM type LEFT JOIN book ON type.card = book.card;

相当于:不断在 type 表中拿一个值,到 book 表中进行全表遍历。
添加索引后:
CREATE INDEX Y ON book(card);
EXPLAIN SELECT SQL_NO_CACHE * FROM type LEFT JOIN book ON type.card = book.card;

对 驱动表 还是全表扫描,被驱动表使用索引
若只能添加一个索引,应添加给被驱动表的连接条件。因为驱动表的数据要全部保留下来
若同时为两个表添加索引,则连接条件中字段的类型必须相同
3.2 内连接
CREATE INDEX Y ON book(card);
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;
CREATE INDEX X ON `type`(card);
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;
结论:在内连接中,查询优化器可以决定哪个表作为驱动表,哪个表作为被驱动表
删除索引
DROP INDEX X ON type;
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;
此时,type表会作为被驱动表,book 表作为驱动表
结论:在内连接中,若只有一个表的连接条件字段有索引,则有索引的表会作为被驱动表,没有索引的表作为驱动表

向type 表中,插入数据
INSERT INTO type(card) VALUES (FLOOR(1 + (RAND() * 20)));
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;
结论:在内连接中,两表的连接条件都有索引的情况下,会选择小表(数据量较少)作为驱动表,大表(数据量较多)作为被驱动表。小表驱动大表
3.4 JOIN 语句原理
1. 驱动表和被驱动表
驱动表就是主表,被驱动表就是从表
-
对于内连接:
SELECT * FROM A JOIN B ON...A不一定是驱动表 -
对于外连接:
SELECT * FROM A LEFT JOIN B ON...
或
SELECT * FROM B RIGHT JOIN A ON...
A也不一定是驱动表
CREATE TABLE a(f1 INT,f2 INT,INDEX(f1)) ;
CREATE TABLE b(f1 INT,f2 INT);
INSERT INTO a VALUES(1,1),(2,2),(3,3),(4,4),(5,5),(6,6);
INSERT INTO b VALUES(3,3),(4,4),(5,5),(6,6),(7,7),(8,8);
SELECT * FROM b;
测试
EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1) WHERE (a.f2 = b.f2);
EXPLAIN SELECT * FROM a LEFT JOIN b ON(a.f1=b.f1) AND (a.f2 = b.f2);
2.Simple Nested-Loop Join (简单循环连接)
不断从表A 中取出一条数据,对 B 表进行全表遍历,将匹配到的数据放到 result 中。
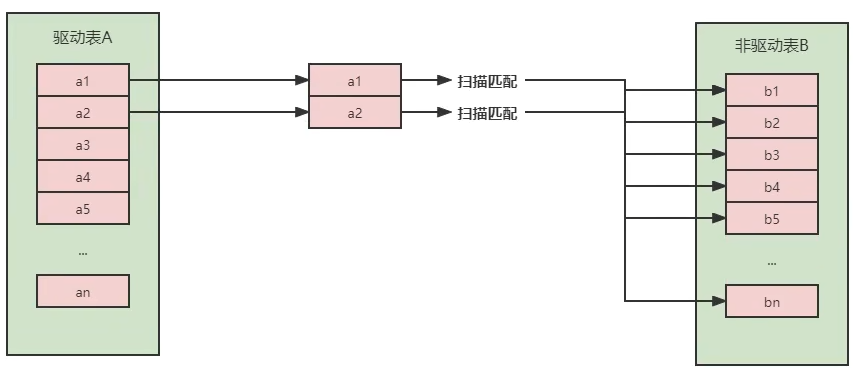
效率较低,若表 A 数据100条,表 B 数据 1000 条计算,则A * B = 10 w次
| 开销统计 | SNLJ |
|---|---|
| 外表扫描次数: | 1 |
| 内表扫描次数 | A表的条目数 |
| 读取记录数 | A表的条目数 + B表条目数* A |
| JOIN比较次数 | B表条目数* A表条目数 |
| 回表读取记录次数: | 0 |
3.Index Nested-Loop Join(索引嵌套循环连接)
其优化思路:为了减少内层表数据的匹配次数。所以会要求 被驱动表上必须有索引才可以优化。
通过驱动表和被驱动表的连接条件直接与被驱动表索引进行匹配,避免了和被驱动表的每条记录去进行比较,减少了对被驱动表的匹配次数
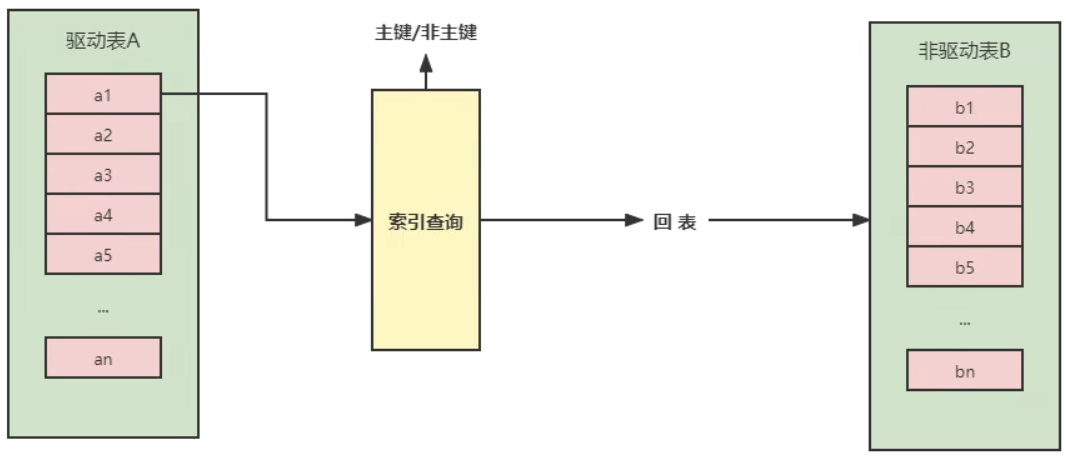
| 开销统计 | SNLJ | INLJ |
|---|---|---|
| 外表扫描次数: | 1 | 1 |
| 内表扫描次数 | A表的条目数 | 0 |
| 读取记录数 | A表的条目数 + B表条目数* A | A+B(match) |
| JOIN比较次数 | B表条目数* A表条目数 | A * index(Height) |
| 回表读取记录次数: | 0 | B(match)(if possible) |
4. Block Nested-Loop Join(块嵌套循环连接)
如果连接条件的字段上没有索引,则被驱动表需要扫描的次数过多。每次比较时,都会将被驱动表的数据全部加载到内存中,然后驱动表的一条数据对被驱动表的所有数据进行依次匹配,匹配结束后清除内存,然后再从驱动表中加载一条记录,再将被驱动表的所有数据加载到内存中进行匹配。这样I/O的次数过多,为了减少被驱动表的I/O 次数,出现了 Block Nested-Loop Join 的方式
不再逐条获取驱动表的数据,而是一块一块的获取在Join Buffer缓冲区。将驱动表 join 相关部分的数据列 缓存到 join buffer 中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和 join buffer 中的所有驱动表进行匹配(内存中操作),将简单嵌套循环中的多次比较合并成了一次,大大降低了被驱动表的访问频率
缓存的不只是关联表的列,select 后面的列也会缓存起来
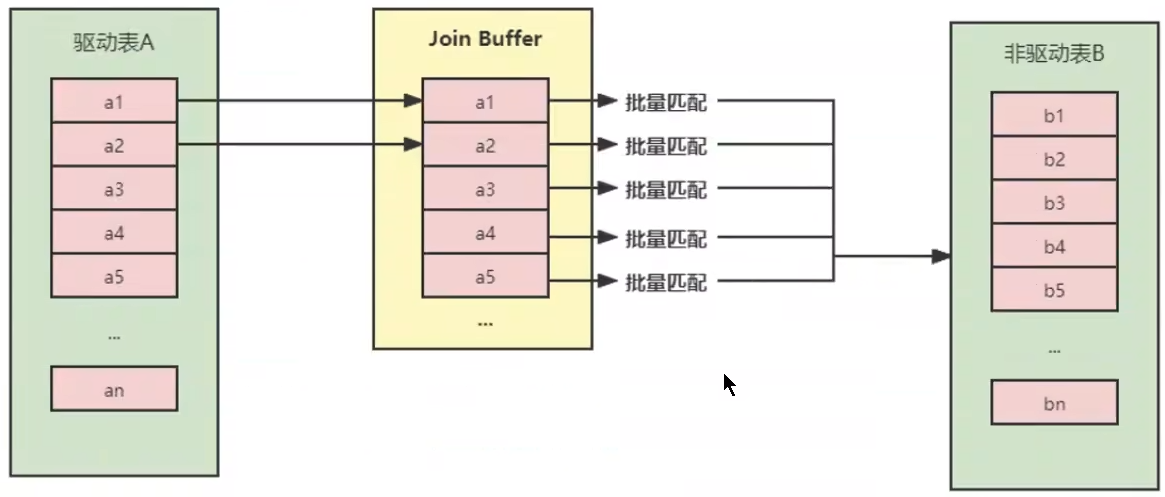
| 开销统计 | SNLJ | INLJ | BNLJ |
|---|---|---|---|
| 外表扫描次数: | 1 | 1 | 1 |
| 内表扫描次数 | A表的条目数 | 0 | A * used_column_size/join_buffer_size+1 |
| 读取记录数 | A表的条目数 + B表条目数* A | A+B(match) | A + B* (A * used_column_size/join_buffer_size) |
| JOIN比较次数 | B表条目数* A表条目数 | A * index(Height) | B * A |
| 回表读取记录次数: | 0 | B(match)(if possible) | 0 |
参数设置:
-
block_nested_loop 通过
show variables like '%optimizer_switch%'查询block_nested_loop状态。默认为开启 -
join_buffer_size 默认为:256K
show variables like '%join_buffer%';
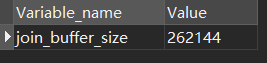 最大值在 32 位系统可以申请 4G,在 64 位可以申请大于 4G 的 Join Buffer (64位 Windows 下,会被截断为 4G 并发出警告)
最大值在 32 位系统可以申请 4G,在 64 位可以申请大于 4G 的 Join Buffer (64位 Windows 下,会被截断为 4G 并发出警告)
5. Join小结
1、整体效率比较:INLJ > BNLJ > SNLJ 2、始终用小结果集驱动大结果集。(为了减少外层循环的数据量)(度量单位:表行数 * 每行大小)
select t1.b,t2.* from t1 straight_join t2 on (t1.b = t2.b) where t2.id <= 100; 推荐
select t1.b,t2.* from t2 straight_join t1 on (t1.b = t2.b) where t2.id <= 100;不推荐
straight_join:不让查询优化器,修改驱动表和被驱动表的顺序
3、为被驱动表匹配条件增加索引(减少内层表的循环匹配次数) 4、增大join buffer size 的大小(一次缓存的数据越多,则内层包的扫表次数就越少) 5、减少驱动表不必要的查询(字段越少,join buffer 缓存的数据就会多)
6、Hash join
MySQL 8.0.20 版本开始废弃BNLJ,从8.0.18 版本开始加入 hash join 并且默认使用
- Nested Loop:
- 对于被连接的数据子集较小的情况,Nested Loop 是一个较好的选择
- Hash Join 是做
大数据集连接时常用的方式,优化器使用两表中较小 的表利用 Join Key 在内层中建立散列表。然后扫描较大的表并探测散列表,找出与 Hash 表匹配的行
| 类别 | Nested Loop | Hash Join |
|---|---|---|
| 使用条件 | 任何条件 | 等值连接(=) |
| 相关资源 | CPU、磁盘I/O | 内层、临时空间 |
3.5 小结
- 保证被驱动表的 JOIN 字段已经创建了索引
- 连接条件字段的数据类型必须保持绝对一致
- LEFT JOIN 时,选择小表作为驱动表,
大表作为被驱动表,减少外层循环的次数 - INNER JOIN 时,MySQL 会自动将
小结果集的表选为驱动表。选择相信 MySQL 优化策略 - 能够直接多表关联的尽量直接关联,不用子查询。
- 不建议使用子查询,建议将子查询 SQL 拆开结合程序多次查询,或使用 JOIN 来代替子查询
- 临时表创建不了索引
4. 子查询优化
子查询可以一次性完成逻辑上需要多个步骤才可以完成的 SQL 操作。
在 MySQL 中,可以使用 连接(JOIN) 查询来替代子查询。连接查询不需要建立临时表,其速度比子查询快。如果在查询中使用索引时,性能会更好
结论:尽量不要使用 NOT IN 或 NOT EXISTS,用 LEFT JOIN xxx ON xx WHERE xxx IS NULL 替代
5. 排序优化
问题:为什么 ORDER BY 字段 推荐添加索引?
回答:
在 MySQL 中,支持两种排序方式,分别是 FileSort 和 Index 排序
- 在 index 排序中,索引可以保证数据的有序性,不需要再进行排序,
效率高 - FileSort 排序在
内存中进行排序,占用CPU 较多。若待排序结果较大,会产生临时文件 I/O 到磁盘进行排序的情况,效率较低。
优化建议:
- 在 SQL 中,WHERE 子句 和 ORDER BY 子句中使用索引,目的是为了在 WHERE 子句中
避免全表扫描,在 ORDER BY 子句中避免使用 FileSort 排序。在某些情况下全表扫描 或 FileSort 排序不一定比索引慢。但是尽量避免 - 尽量使用 Index 来完成 ORDER BY 排序。若 WHERE 和 ORDER BY 后面是相同的列就使用单索引列;若不同则使用联合索引
- 无法使用 Index 时,需要对 FileSort 方式进行调优
5.4 filesort算法:双路排序和单路排序
若排序的字段不在索引列上,则 filesort 会有两种算法:双路排序和单路排序
双路排序(慢)
MySQL 4.1 之前是使用双路排序,两次扫描磁盘,最终得到数据,读取行指针和order by列,对其进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出- 从磁盘取排序字段,在 buffer 进行排序,再从
磁盘取其他字段
取一批数据,要对磁盘进行两次扫描。mysql 4 之后,出现了改进算法:单路排序
单路排序(快) 从磁盘读取查询需要的 所有列,按照order by 列在 buffer 进行排序,然后扫描排序后的列表进行输出,它的效率更快一些,避免了第二次读取数据。并且把随机I/O 变成顺序 I/O 但是会使用更多的空间,因为它把每一行都保存在内存中。
引申出的问题:
- 在 sort_buffer 中,单路比多路
更加占用空间,单路是将所有字段取出,可能取出的数据大小超出了sort_buffer的容量,导致每次只能取 sort_buffer 容量大小的数据,进行排序,排完再取 sort_buffer 容量大小,再排.....从而导致多次 I/O - 单路目的是想要节省 一次 I/O 次数,这样
反而导致了大量的I/O操作
优化策略 1.尝试提高 sort_buffer_size
- 不管用哪种算法,提高该参数都会提高效率。这个参数是针对每个进程的 1M-8M 之间调整。MySQL 5.7 中InnoDB 存储引擎默认值是 1048576 字节,1MB
SHOW VARIABLES LIKE '%sort_buffer_size%';
2.尝试提高 max_length_for_sort_data
- 提高这个参数,会增加用改进算法的概率
SHOW VARIABLES LIKE '%max_length_for_sort_data%';
3.Order By 时 select * 是一个大忌。最好只 Query 需要的字段 原因:
- 当 Query 的字段大小总和小于
max_length_for_sort_data,并且排序字段不是 TEXT|BLOB 类型时,会用单路排序,否则会使用多路排序
6. GROUP BY 优化
- group by 使用索引的原则几乎是和 order by 一致,group by 即使没有过滤条件用到索引,也可以直接使用索引
- group by 先排序再分组,仍然遵循索引的最佳左前缀法则
- 当无法使用索引列 ,增大
max_length_for_sort_data和sort_buffer_size参数 - where 效率高于 having,能写在 where 中就不要写在 having 中
- 减少使用 order by,或将排序放到程序端去做。Order By、group by、distinct 语句较耗费 CPU
- 包含 order by、group by、distinct 语句,where 条件过滤出的结果集请保持在 1000 行以内,否则 SQL 会很慢
7.优化分页查询
举例:
EXPLAIN SELECT * FROM student LIMIT 20000000,10;
此时,MySQL需要排序前 20000010 记录,后仅仅范围 20000000 - 20000010的记录,其他记录丢弃,查询排序的代价很大
优化思路一
在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容
EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 20000000,10 ) a WHERE t.id = a.id;
优化思路二
适用于主键自增的表,可以将 Limit 查询转换为 某个位置的查询
EXPLAIN SELECT * FROM student WHERE id > 20000000 LIMI 10 ;
8. 优先考虑覆盖索引
8.1 什么是覆盖索引
一个索引中包含了 需要查询的所有字段 就叫覆盖索引。
或
非聚簇索引的一种形式,包括了在 查询中的 SELECT 、JOIN 和 WHERE 子句用到的所有列(即索引的字段覆盖了查询条件中所涉及的所有字段)
总结:索引列 + 主键 包含 SELECT 到 FROM 之间查询的列
举例:
删除之前的索引
DROP INDEX idx_age_stuno ON student;
CREATE INDEX idx_age_name ON student(age,NAME);
EXPLAIN SELECT * FROM student WHERE age <> 20;

覆盖索引
EXPLAIN SELECT age,name FROM student WHERE age <> 20;

举例二:
CREATE INDEX idx_age_name ON student(age,name);
EXPLAIN SELECT * FROM student WHERE name LIKE '%abc';

EXPLAIN SELECT id,age,name FROM student WHERE name LIKE '%abc';

8.2 覆盖索引的利弊
好处:
1.避免InnoDB 表进行索引的二次查询(回表)
在覆盖索引中,二级索引的键值已经可以获取到需要查找的数据,避免对于主键的二次查询,减少 I/O 操作
2.可以将随机I/O变成为顺序I/O加快查询效率
在非聚簇索引(二级索引中)的顺序,和在 主键索引中的顺序可能不一致,所以回表时,可能导致变成随机 I/O
覆盖索引可以减少树的搜索次数,明显提升查询性能。使用覆盖索引是一个常用的性能优化手段
弊端:
索引字段的维护有代价。
9. 如何给字符串添加索引
9.1 前缀索引
MySQL 中支持前缀索引。若创建语句中没有指定指定长度,则索引会包含整个字符串
mysql> alter table teacher add index index1(email);
#或
mysql> alter table teacher add index index2(email(6));
9.2 影响
优点:可以节省空间 缺点:使用前缀索引就无法使用覆盖索引对查询性能的优化
10.索引(条件)下推
10.1 使用前后对比
Index Condition Pushdown(ICP) 是 MySQL 5.7 的新特性,是在存储引擎层使用索引过滤数据的优化方式。普遍使用在联合索引中
举例:
EXPLAIN SELECT * FROM s1 WHERE key1 > 'z' AND key1 LIKE '%a';
若二级索引中包含查询条件后面的字段,则在进行回表操作之前,会进行索引下推
即:在回表之前完成后部分的条件判断。这样会大大减少回表后需要查询的数据
举例二:
key zip_last_first (`zipcode`,`lastname`,`firstname`)
EXPLAIN SELECT * FROM people
WHERE zipcode = '000001'
AND lastname LIKE '%张%'
AND address LIKE '%北京市%';
10.2 ICP 的开启/关闭
- 默认情况下启用索引条件下推,可以通过 系统变量
optimizer_switch控制:index_condition_pushdown
关闭索引下推
SET optimizer_switch = 'index_condition_pushdown=off';
打开
SET optimizer_switch = 'index_condition_pushdown=on';
- 当使用索引条件下推时,
EXPLAIN语句输出结果中Extra列内容显示为Using index condition
10.4 ICP 的使用条件
- 表的访问类型为 range、ref、eq_ref 和 ref_or_null 可以使用 ICP
- ICP 可以用于
InnoDB和MyISAM - 对于
InnoDB表,ICP 仅适用于二级索引。ICP 目的:减少回表行为 - 使用 覆盖索引时,不支持 ICP
- 相关子查询的条件不能使用 ICP
12.其他查询优化策略
12.1 EXISTS 和 IN 的区分
选择标准主要为:小表驱动大表
举例:哪个表小就用哪个表驱动,A表小就用 EXISTS ,B表小就用 IN
SELECT * FROM A WHERE cc IN (SELECT cc FROM B)
SELECT * FROM A WHERE EXISTS (SELECT cc FROM B WHERE B.cc=A.cc)
当 A 小于 B 时,用 EXISTS。因为 EXISTS 的实现,相当于外表循环。 类似于
for i in A
for j in B
if j.cc == i.cc then...
当 B 小于 A 时,用 IN
for i in B
for j in A
if j.cc == i.cc then...
12.2 COUNT( * )与 COUNT(具体字段)效率
在 MySQL 中,统计数据表的行数,有三种方式:SELECT COUNT(*) 、SELECT COUNT(1)和 SELECT COUNT(具体字段)
环节1: COUNT(*) 和 COUNT(1) 本质上没有区别(执行时间可能略有区别,但是可以看作执行效率是相等的)
环节2: 若使用 MyISAM 存储引擎,统计表行数只需要 O(1) 的复杂度。因为 有MyISAM 中有一个 meta 信息存储了 row_count 值,而一致性由表级锁来保证
若使用 InnoDB 存储引擎,因为 InnoDB 支持事务,采用 行级锁和 MVCC 机制,所以无法像 MyISAM 一样,维护一个 row_count 变量,因此需要采用 扫描全表,是 O(n) 的复杂度,进行循环 + 计数的方式来完成统计。
环节3:在 InnoDB 中,若使用 COUNT(具体字段) 来统计行数,尽量使用 二级索引。因为主键索引中包含的数据较多,明显大于 二级索引。而COUNT(*) 和 COUNT(1) 来说,不需要查询具体的行,只是统计行数,系统会 自动 采用占用空间更小的二级索引来统计。
若有多个二级索引,会使用 key_len 小的二级索引进行扫描,若没有二级索引时,才会使用主键索引来统计。
12.3 关于 SELECT(*)
建议不要使用 * 作为查询的字段列表,推荐使用 SELECT 字段列表 查询。
原因:
- MySQL 在解析时,会通过
查询数据字典将 * 按需转换为所有列名,会损耗较多的资源和时间 - 无法使用
覆盖索引
12.4 LIMIT 1 对优化的影响
若是扫描全表的 SQL 语句,若已经确定结果集只有一条,则可以加上 LIMIT 1 ,当找到了一条记录结果时就不会继续扫描了,可以加快查询速度
若字段已经建立了唯一索引,则可以通过索引进行查询,就不需要加上 LIMIT 1
12.5 多使用 COMMIT
尽量多使用 COMMIT,可以提高性能。原因:COMMIT 会释放资源
COMMIT 所释放的资源:
- 回滚段上用于恢复数据的信息
- 被程序语句获取的锁
- redo / undo log buffer 中的空间
- 管理上述 3 种资源种的内部花费
13. 淘宝数据库,主键如何设计的?
13.1 自增 ID 的问题
1. 可靠性不高 存在自增 ID 回溯问题,MySQL8.0 才修复 2. 安全性不高
3. 性能差
4. 交互多
还需要额外执行一次类似 last_insert_id() 的函数才知道刚插入的自增值
5. 局部唯一性
只是在按当前数据库中唯一,而不是全局唯一
13.2 业务字段做主键
举例:为其设计主键
- 选择卡号(cardno) 如果出现卡号重复使用的情况,修改该表时的数据。会出现与其关联的表的数据没有修改,例如:消费记录等
- 手机号码或者身份号码 手机号存在被回收的情况,重新发放给别人使用 身份找号码属于个人隐私,不一定告知
所以,建议尽量不要使用跟业务相关的字段做主键。
13.3 淘宝的主键设计
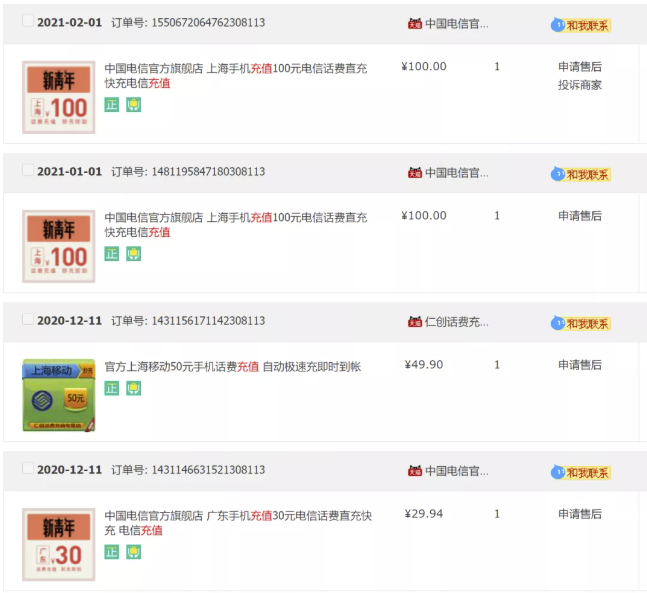
从上图可以发现,订单号不是自增 ID
1550672064762308113
1481195847180308113
1431156171142308113
1431146631521308113
可以大胆猜测
订单ID = 时间 + 去重字段 + 用户ID后6位
这样可以设计做到全局唯一,且对分布式系统查询及其友好
13.4 推荐的主键设计
非核心业务:对应表的主键自增ID,如告警、日志、监控等信息
核心业务:主键设计至少应该是全局唯一且是单调递增。 全局唯一是保证在各系统之间都是唯一的,单调递增是希望插入数据时不影响数据库性能
推荐最简单的一种主键设计:UUID UUID 的特点: 全局唯一,占用 36 字节,数据无序,插入性能差
组成:
UUID = 时间 + UUID 版本(16字节) - 时间序列(4字节)- MAC地址(12字节)
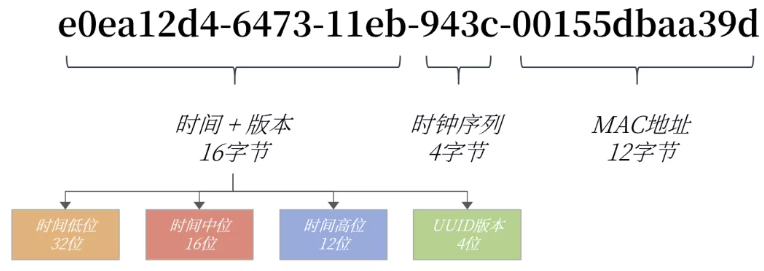
改造 UUID MySQL8.0 可以更换时间高位和时间地位的存储方式,这样就是有序的UUID
MySQL8.0 解决了 UUID 存在空间占用的问题,除去了UUID 字符串中无意义的 "-" 字符串,并且将字符串用二进制类型保存,存储空间降低为了 16 字节
可以通过使用 uuid_to_bin 函数实现上述功能,MySQL 还提供了 bin_to_uuid 函数进行转换
SET @@uid = UUID();
SELECT @uuid,uuid_to_bin(@uuid),uuid_to_bin(@uuid,TRUE);

通过 uuid_to_bin(@uuid,true) 可以将 UUID 转化为 有序UUID。这样就可以实现 全局唯一 + 单调递增。
4、有序 UUID 性能测试
测试:插入1亿条数据,每条数据占用 500 字节,含有 3 个二级索引
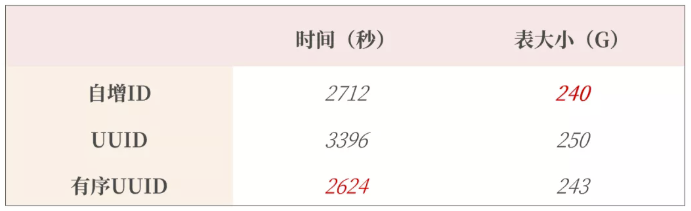
上图可以看出插入 1 亿条数据有序UUID 是最快的,并且实际业务使用中有序UUID在 业务端可以生成
若不是MySQL 8.0 ,则手动赋值字段做主键
—SQL 优化服务器调优及各个参数设置(缓冲、线程数等)—调整 my.cnf数据过多 — 分库分表SQL 查询优化可以分为:物理查询优化 和 逻辑查询优化物理查询优化:通过索引 和 表连接方式 等技术进行优给,重点需){kind=link}
—SQL 优化服务器调优及各个参数设置(缓冲、线程数等)—调整 my.cnf数据过多 — 分库分表SQL 查询优化可以分为:物理查询优化 和 逻辑查询优化物理查询优化:通过索引 和 表连接方式 等技术进行优给,重点需){kind=link}